
컴퓨터에는 숫자, 특수 기호, 한글, 영어 등 다양한 문자가 사용되는데, 이들을 구별하기 위해서는 각 문자를 유일한 값으로 표현하는 코드 체계가 필요합니다. 대표적인 코드 체계로는 아스키코드(ASCII), 2 진화 10진 코드(BCD), 확장 2 진화 10진 코드(EBCDIC), 유니 코드(Unicode) 등이 있습니다. 먼저 아스키코드에 대해서 알아보겠습니다.
아스키코드(ASCII : American Standard Code for Information Interchange)는 미국표준협회(ANSI : American National Standards Institute)가 제정한 데이터 처리 및 통신시스템 상호 간의 정보 교환용 표준 코드입니다. 각 문자를 나타내기 위해 7비트가 사용되지만, 데이터 전송 시 오류 검사를 위한 패리티 비트(Parity bit)를 추가하여 8비트가 사용됩니다. 표현할 수 있는 문자는 영문, 대문자 및 소문자, 구두점 기호, 숫자를 비롯해 128(27)개 입니다. ASCII 코드는 아래의 그림과 같이 7비트 중 앞의 3비트는 존(Zone) 비트를, 뒤의 4비트는 디지트(Digit) 비트를 나타냅니다.

확장 아스키 코드 표

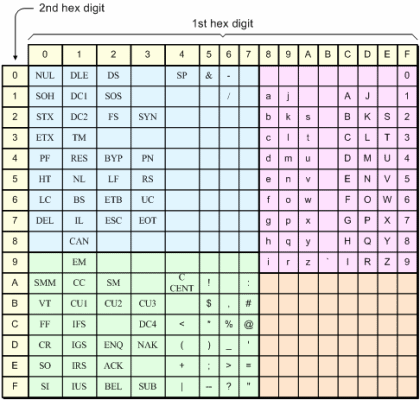
위의 표에서 0~31번과 127번은 데이터 통신, 화면 및 프린터 제어용 문자 코드를 나타내고, 32~64번은 특수문자 및 숫자 코드를 나타냅니다. 65~96번은 대문자와 특수문자, 97~126번은 소문자와 특수문자를 나타냅니다. 128개의 문자로는 다양한 데이터를 표현하기 어렵기 때문에 ASCII 코드의 존 비트를 4 비트로 확장한 확장 아스키코드(ASCII)를 사용해 다양한 데이터를 표현합니다.
2 진화 10진 코드
컴퓨터에서 10진수는 2 진화 10진 코드(BCD : Binary Coded Decimal)로 나타냅니다. BCD 코드는 문자 하나를 표현하기 위해 6비트를 사용하므로 64(26)개의 문자를 표현할 수 있습니다. 아래의 그림과 같이 4비트의 디지트 비트에 2비트의 존 비트를 추가해 10진수 숫자와 문자를 표현합니다. 존 비트는 디지트 비트가 어느 조에 속하는지 나타냅니다. 디지트 비트는 0~9까지의 수를 표현하는 가중치 코드(Weighted Code)로 자릿값을 갖기 때문에 8421 코드라고도 합니다.

확장 2진화 10진 코드
IBM사가 문자 코드에 대한 필요성으로 제정하게 된 확장 2 진화 10진 코드(EBCDIC : Extended BCD)는 IBM의 메인프레임 컴퓨터에서 사용합니다. EBCDIC는 표준 BCD 코드를 8비트로 확장한 것인데, 아래의 그림과 같이 4비트의 존 비트와 4비트의 디지트 비트로 구성되어 256(28)개의 문자를 표현할 수 있습니다.
유니코드
유니코드(Unicode)는 전 세계의 언어를 일관된 방법으로 표현하고 다룰 수 있는 국제적인 문자 코드 규약입니다. 문자 하나를 16비트로 표현하므로 65,536(216)개의 문자와 기호를 나타낼 수 있습니다. 애플, IBM, 마이크로소프트 등이 컨소시엄으로 설립한 유니코드는 1990년에 첫 버전을 발표했고, 1995년 9월 국제 표준으로 제정되었습니다.
유니코드가 지원하는 인코딩 방식은 UTF(UCS Transformation Format)-8, UTF-16, UTF-32 세 가지가 있습니다. UTF 뒤의 숫자는 문자 인코딩에 사용되는 비트 수를 나타냅니다. 즉 UTF-8은 8비트, UTF-16은 16비트, UTF-32는 32비트 단위로 문자를 표현합니다. 세 가지방식은 16개의 보충 언어판에 위치판 1,048,576개의 코드를 표현할 때 4바이트를 사용한다는 공통점이 있습니다. 차이점으로는 UTF-8은 4개의 8비트, UTF-16은 2개의 16비트, UTF-32는 1개의 32비트 단위로 표현한다는 것입니다.
언어별 유니코드 차트 자료는 이곳에서 확인할 수 있습니다.

'IT' 카테고리의 다른 글
| 컴퓨터의 정수 표현 (0) | 2020.12.05 |
|---|---|
| 정보의 표현 중 비트와 바이트, 그리고 워드는 무엇인가? (0) | 2020.11.27 |
| 진법 변환 (0) | 2020.11.24 |



